Adobe’s top technologist on what makes an AI tool good enough to launch
Adobe entered the modern era of generative AI a full year behind others, and the company continues moving forward with Firefly at a conservative pace. It’s a strategy you could criticize—or argue is by design. Adobe needs to push the boundaries of media without breaking the tools used by its creative customers every day, like graphic designers and video editors.While Adobe first debuted Firefly tools in Photoshop in 2023, it took about a year for them to be any good. Now, it’s upping the ante by going from generating still imagery to motion. Adobe is moving some of its video generation tools, first teased in April, into private beta. The new options appear powerful, but for Adobe, it’s as important that these tools are practical. Adobe needs to master the UI of AI.Text to Video is basically Adobe’s answer to OpenAI’s Sora (which is also yet to be released publicly). It lets you type a prompt, like “closeup of a daisy,” to generate video of it. Adobe’s distinguishing feature is cinemagraphic creative control. A drop down menu will share options like camera angles to help guide you in the process.Another feature, Generative Extend, pushes AI integration a step further—and I think is Adobe’s best example of how gen AI can sneak into a UI workflow. It allows you to take a clip in Premiere Pro and simply stretch it longer on the timeline, while the system will invent frames (and even background audio) to fill the time. You can see in the clip below where an astronaut, in close up, gets the stretch treatment, which he fills by ever so gently turning his head. Inspired? No. Easy? Yes. Convincing? Absolutely. In a conversation with Adobe CTO, Ely Greenfield, I took the opportunity to probe into Adobe’s psyche. How is it thinking about integrating AI tools? What constitutes success? What defines a useful AI feature? In our 30-minute conversation, Greenfield offered a candid look at the processes and priorities behind Adobe’s integration of gen AI. This interview has been edited and condensed for clarity.Fast Company: OK, what’s the stickiest AI feature Adobe has shipped so far?Ely Greenfield: Generative Fill and Generative Expand in Photoshop are incredibly sticky and valuable. The last number we quoted was over 9 billion images generated. A lot of that is Generative Fill and Expand in Photoshop. Generative Remove in Lightroom is also coming up strong. We’ve seen a huge explosion and growth in that as well.How well does a generative AI tool need to work to make it into an Adobe product? Does the result need to be acceptable nine out of ten times, for instance? Or like, two out of ten?It comes down to what the problem is and what the next best alternative is. If someone is looking for fairly common stock, like b-roll, then it better get it right 100% of the time, because even then, you could just use b-roll. But if you have specificity to what you want…getting it right 1/10 times is still a huge savings. It can be a little frustrating in the moment, but if we can give people good content 1/10 times that saves them from going back to reshoot something on deadline, that’s incredibly valuable.Our goal is 10/10 times. But the bar to get into people’s hands to provide value to them in a deadline crunch is much closer to 1/10 times. I’m tempted to give a number on where we are now, but it varies wildly on the use case.[Image: Adobe]I’ve been a professional producer and editor. I know what it’s like to not have that shot in the 11th hour and to feel desperate. But I also always expect an Adobe product to work. So explaining that AI might work one out of ten times,—and why—seems like a communication challenge for Adobe. It’s a real mess for Google AI that its search results are so often wrong, when the standard results right below them are correct—no wonder you have the public complaining that Google is telling you to put glue on a pizza.For Google, hallucination is the bane of their existence. For us, it’s what you’re coming to Firefly for. Google you get the answer, and there’s such an activation energy: Do I trust this? Now I have to validate it! Is the work worth it, or would [traditional] search have been better?When we generate, it’s not a question of, can I trust it? It’s just about what’s in front of your eyes. I can make that judgment instantly. If I like it, I can use it. It’s a little more understandable. The use cases we’re going after are ones where the next best alternative is expensive and painful: I don’t have an option, it’s the night before a deadline, and I can’t create this myself. Those are the use cases we’re going after. If we can save you 50% of your time, and even if you spend an hour generating, that’s a lot of time you saved over the alternative. We have to make sure we’re talking to the right customers who say this is going to save them time versus people playing around, saying it took too long. We want to create real value.[Image: Adobe]How easy should generative AI be to use? I watch how my son,
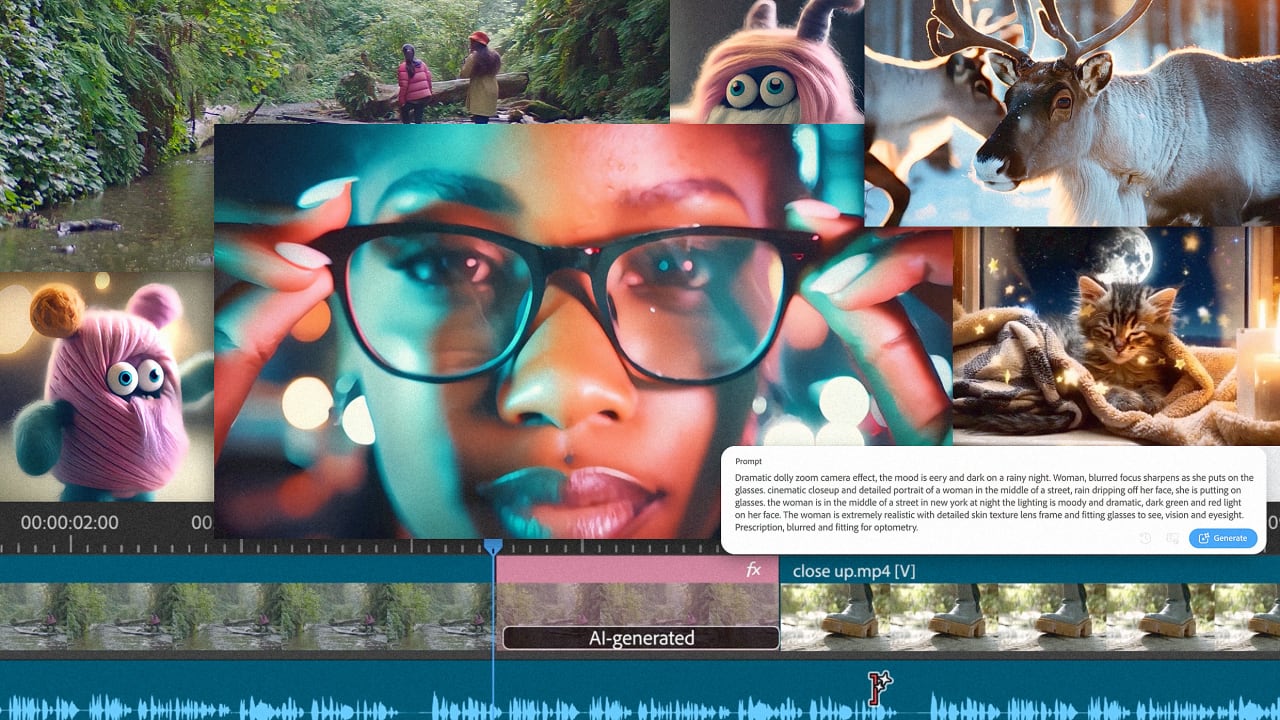
Adobe entered the modern era of generative AI a full year behind others, and the company continues moving forward with Firefly at a conservative pace. It’s a strategy you could criticize—or argue is by design. Adobe needs to push the boundaries of media without breaking the tools used by its creative customers every day, like graphic designers and video editors.
While Adobe first debuted Firefly tools in Photoshop in 2023, it took about a year for them to be any good. Now, it’s upping the ante by going from generating still imagery to motion.
Adobe is moving some of its video generation tools, first teased in April, into private beta. The new options appear powerful, but for Adobe, it’s as important that these tools are practical. Adobe needs to master the UI of AI.
Text to Video is basically Adobe’s answer to OpenAI’s Sora (which is also yet to be released publicly). It lets you type a prompt, like “closeup of a daisy,” to generate video of it. Adobe’s distinguishing feature is cinemagraphic creative control. A drop down menu will share options like camera angles to help guide you in the process.
Another feature, Generative Extend, pushes AI integration a step further—and I think is Adobe’s best example of how gen AI can sneak into a UI workflow. It allows you to take a clip in Premiere Pro and simply stretch it longer on the timeline, while the system will invent frames (and even background audio) to fill the time. You can see in the clip below where an astronaut, in close up, gets the stretch treatment, which he fills by ever so gently turning his head. Inspired? No. Easy? Yes. Convincing? Absolutely.
In a conversation with Adobe CTO, Ely Greenfield, I took the opportunity to probe into Adobe’s psyche. How is it thinking about integrating AI tools? What constitutes success? What defines a useful AI feature? In our 30-minute conversation, Greenfield offered a candid look at the processes and priorities behind Adobe’s integration of gen AI.
This interview has been edited and condensed for clarity.
Fast Company: OK, what’s the stickiest AI feature Adobe has shipped so far?
Ely Greenfield: Generative Fill and Generative Expand in Photoshop are incredibly sticky and valuable. The last number we quoted was over 9 billion images generated. A lot of that is Generative Fill and Expand in Photoshop. Generative Remove in Lightroom is also coming up strong. We’ve seen a huge explosion and growth in that as well.
How well does a generative AI tool need to work to make it into an Adobe product? Does the result need to be acceptable nine out of ten times, for instance? Or like, two out of ten?
It comes down to what the problem is and what the next best alternative is. If someone is looking for fairly common stock, like b-roll, then it better get it right 100% of the time, because even then, you could just use b-roll. But if you have specificity to what you want…getting it right 1/10 times is still a huge savings. It can be a little frustrating in the moment, but if we can give people good content 1/10 times that saves them from going back to reshoot something on deadline, that’s incredibly valuable.
Our goal is 10/10 times. But the bar to get into people’s hands to provide value to them in a deadline crunch is much closer to 1/10 times. I’m tempted to give a number on where we are now, but it varies wildly on the use case.
I’ve been a professional producer and editor. I know what it’s like to not have that shot in the 11th hour and to feel desperate. But I also always expect an Adobe product to work. So explaining that AI might work one out of ten times,—and why—seems like a communication challenge for Adobe. It’s a real mess for Google AI that its search results are so often wrong, when the standard results right below them are correct—no wonder you have the public complaining that Google is telling you to put glue on a pizza.
For Google, hallucination is the bane of their existence. For us, it’s what you’re coming to Firefly for. Google you get the answer, and there’s such an activation energy: Do I trust this? Now I have to validate it! Is the work worth it, or would [traditional] search have been better?
When we generate, it’s not a question of, can I trust it? It’s just about what’s in front of your eyes. I can make that judgment instantly. If I like it, I can use it. It’s a little more understandable.
The use cases we’re going after are ones where the next best alternative is expensive and painful: I don’t have an option, it’s the night before a deadline, and I can’t create this myself. Those are the use cases we’re going after.
If we can save you 50% of your time, and even if you spend an hour generating, that’s a lot of time you saved over the alternative. We have to make sure we’re talking to the right customers who say this is going to save them time versus people playing around, saying it took too long. We want to create real value.
How easy should generative AI be to use? I watch how my son, a 4th grader, is using Canva’s generative AI tools. Because they’re so accessible in the workflow, I notice that he often generates images for things I know already exist in Canva’s own stock library. It feels like a waste of time and energy! Is this something Adobe is thinking about?
We absolutely are working on it. I was reviewing some UIs yesterday showing how some stuff is [being incorporated] into tools. Generally, the concept is to generate a search. For all sorts of reasons, if what you’re working on can be solved with licensable content, why generate? It’s a waste of time, money, CO2. We’re not trying to compete with existing stock out there. We look at where stock isn’t good enough.
For the customer, once we get past the gee-whizz-wow factor, what matters is you get a piece of content. You don’t care where it came from. Hopefully you care how it’s licensed! But at the end of the day, whether it’s manually captured or AI-generated doesn’t matter as long as you get what you want.
With stock, a lot of the times you get close but not quite there, which is why Generative Fill and Erase are so important. You can combine those tools and take stock content not found and change the color of their jacket. The creative process is iteration. Maybe I find stock content, and that gives me the broad strokes. Then I use generative editing…and then maybe [manual] editing where generative doesn’t work.
In your demo from April, you show Generative Fill working in video, letting someone draw a bounding box in a suitcase, and suddenly it’s filled with diamonds. Is that coming to the beta? Because the UI integration looks incredible. But it seems like most of what you’re showing now isn’t Adobe AI integrated with Adobe UI. It’s still mostly just traditional text prompt generation.
It’s not in beta right now. It’ll follow. The way these things develop, you need a strong foundation model. Right now that ability is text-to-video or image. Once we have that foundation model, then we build use cases: features, applications, and specializations on top of those. Generative Extend is the first one because it requires the least amount of work.
Image-to-video is in private beta now. Generative Extend is image-to-video, basically. But it’s the easiest to polish and take on top of the core foundation. The others will follow, but we don’t have a timeline on them right now.
So you have your core AI intelligence in the foundation model, and then you basically create a UI out of that?
We build an early model, then hand them to teams to fine tune for use cases. Then we iterate on the foundation model. If we uplevel resolution or framerate, then we have to go back to the drawing board with some new features.
You’ve talked about, not just letting someone create video, but giving them granular control over the camera type and aesthetic. Right now, that’s all based upon text descriptions. But I assume you’re looking into building a UI for virtual directing, too? Like we see in After Effects?
You can see some of the evolution of that [in our model]—and there are two pieces to it.
First, we started with basic wide angle and close up, then you could specify depth of field, aperture and focal length. We got more specific about what it can understand. It doesn’t understand codecs, or a Canon vs Nikon, but it does understand camera motion types. Lens style. Camera positioning.
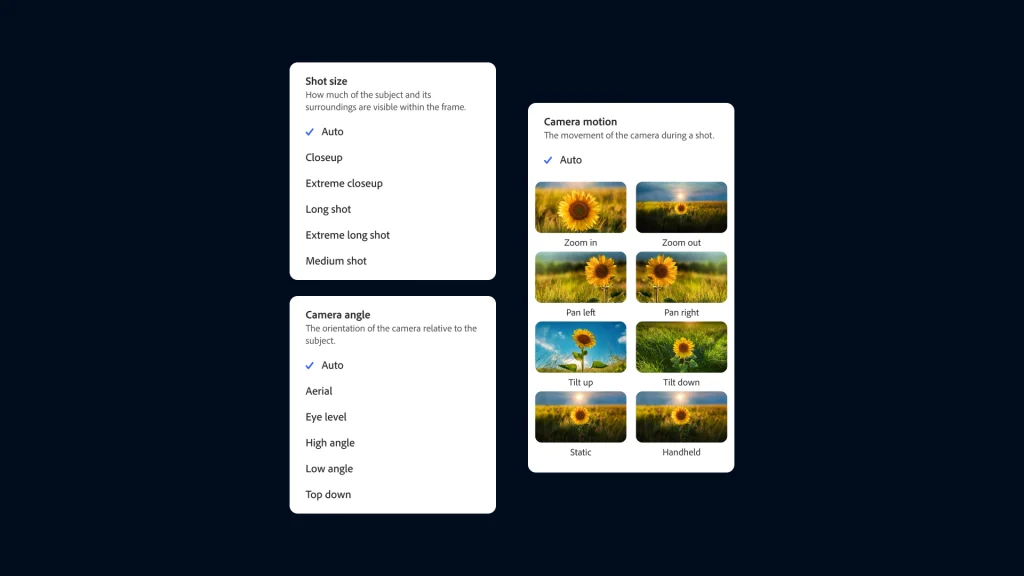
The second piece is absolutely, how do you get into more interactive multimodal input instead of text input?
That starts with an [automatic] prompt from a drop down…so you don’t have to figure out what to type. To then storyboarders. There’s a specified language of camera angle within storyboards: [We might] give you tools to draw and specify camera angles.
But for now, it’s about foundational technology and getting it into someone’s hands.